-
Posted on
Ups and downs of compile time assembler
Hey ho, Over two months ago I shared a teaser for the project I was about to start. Contrary to my other brilliant-yet-useless projects, this one got some traction. The name of the game is “x86 assembler at compilation time”.
Here is a little teaser of things to come. :) pic.twitter.com/crOvbNnCCj
— Piotr Osiewicz (@PiotrOsiewicz) April 13, 2020This is karta. At the very beginning I envisioned it just like I promoted it - the syntax would be close to x86 Intel syntax asm, but nooot quite. Having spent a lot of time prototyping it though, it now looks closer to:
using namespace karta::x86; // Second operand's type determines immediate size. // That's not something I like, but I guess it has it's pros. mov(eax, std::uint8_t(8)); mov(eax, cs[eax]); mov(edx, cs[1234]); mov(ecx, edx); mov(eax, ds[edx + eax * _2]);In my opinion that’s way nicer than the previous syntax (which screamed I AM A TEMPLATE to the user). Also, all of that is legal karta syntax.
Hold up - why bother with all of that? The project probably requires a lot of tedious work? What if you make a mistake? How are the compile times? So..
Why bother?
Having spent a bit of time looking at code of some JIT engine which constructed the instructions byte by byte I wished it was more readable. I’m a total rookie with asm encodings, so looking at DSL for x86 asm would certainly be more pleasant. That’s how karta came about.
Taking the first step
I started by probing the interest on Twitter for DSL asm library - in hindsight it was a good decision, as I felt it kept me accountable. The probe got pretty popular (by my Twitter standards). Thus I got to coding my first instruction - mov. After implementing I think two variants (“mov reg, imm” and “mov reg, reg”) I noticed that I’m in dire needs of tests - after all, the amount of possible instruction encodings was enormous. This is why I’m currently working on a subproject named tcg, which - given specification of instructions (“what kind of arguments does it take”) - can generate .nasm files, convert them to .obj files and generate unit tests (currently based on Catch2) with karta call result being the value that’s compared against. There is one tiiiiny issue - test cases for unfinished mov implementation take half an hour to generate. It’s a tip of the iceberg - are many possible encodings. I’m not gonna wait around for my builds to finish! Karta itself is not an offender here - the snippets are pretty lightweight.. But in case of mov there were 100 000 test cases that the compiler had to chew through in single translation unit. Ouch!
… and immediately fumbling over
So this is what I am currently struggling with. I want tcg to scale, as the biggest hurdle so far was getting memory encoding right. I believe that if tests would be quick to build, I could iterate up to full x86 asm parity within two months of work.
Of course there are other issues on the horizon - some of which are not that big of an issue anymore. One of them was cross-calling to C++ code (e.g: call(std::printf);). There’s an issue: it can’t be constexpr. The address of an entity is not known until link time and that’s (probably) why reinterpret_cast is banned in constexpr context (reinterpret_cast to const char* would do the trick for me, but.. tough luck). Therefore while it might be allowed, I’m not sure if it would be your daily way to use karta.
How you can help
It would be easier for me if I knew what qualities would make karta valid for your use case (assuming permissive license):
- Do you have an use case for karta in some of your projects?
- If so, do you care about everything being constexpr?
- Can your project use C++20?
Answers to these questions would guide my work a bit - right now I’m the sole potential user, so the project reflects my needs. :)
Thanks for taking your time to read through all of that. Have a good day!
-
Posted on
Reduction of C++ project build time - Templates
Hello! I hope you were not starving for some build time reduction tips. It’s been looong two weeks. In case you’ve missed out on the last post, it can be found here. Give it a go!
We now have all the necessary tools to deal with one of the build time offenders - templates. Before we take them on, let’s take a step back and make up few assumptions.
-
Template entities (either class templates or functions) can be thought of as “generators” of entities. It would be wrong to assume that an ordinary function is equal to template definition. Instantiated entity is closer to the plain function than the template definition that was used to create it.
-
This post will deal exclusively with function/method templates - class templates costs cannot really be avoided in cases where a full type needs to be known.
Instantiated functions are implicitly marked with inline specifier. Note that this does not necessarily force compiler to inline all calls to instantiated functions. inline simply allows for multiple occurences of the same symbol to exist across many translation units during linking stage (it makes the emitted symbol weak).
“And so you were born” - template instantiation methods
While we are at it, let’s look into two methods of instantiating templates. These are implicit and explicit instantiations. In my experience most of the instantiations are implicit.. which is a shame, because it is easy to get carried away with template madness this way.
Implicit instantiation
Implicit instantiation takes place whenever the template with given set of template argument is referenced and the full definition of type/function/method has to be known.
// .h file template<typename T> size_t mySizeof() { return sizeof(T); } size_t foo() { return mySizeof<uint32_t>(); // implicit instantiation takes place here. }This also applies to types. Here’s a riddle for you. When does implicit instantiation take place in the following piece of code?
// .h file template<typename T> struct Wrapper{ T value; }; uint32_t foo(Wrapper<uint32_t>* val); uint32_t foo(Wrapper<uint32_t> second_val);I would not ask if it was not a trick question. The instantiation will take place for
Wrapper<int> second_valversion due to the fact that - in pointer case - compiler does not need to know anything about the typeWrapper<int>to emit a valid function call for this type. It also knows it`s size (pointer size depends only on the architecture). However, in case of function definitions there might be an implicit instantiation even in case of pointers. Consider following example:uint32_t foo(wrapper<uint32_t>* val) { return val->value;// member offset from pointed-to-address has to be known here. // Implicit instantiation of type wrapper<uint32_t> takes place. } uint32_t foo(wrapper<uint32_t> val) { // Implicit instantiation has taken place earlier on. // There's nothing to do from compiler perspective. return val.value; }Explicit instantiation
Explicit instantiation is - well, how do I put it - explicit. It can be achieved in a following way.
template class wrapper<uint64_t>;This might not be of much use for your day-to-day work. It will come in handy in just a second.
What is wrong with templates, again?
Templates are wonderful, but in my honest opinion they can impact the build time when used carelessly. Each translation unit that makes use of given template must have a full access to it`s definition in order to use it`s output for given argument list - as it always has to instantiate it (either implicitly or explicitly). Thus, there is a great opportunity for doing redundant work -
mySizeofmight`ve been cheap to instantiate, but in case of more sophisticated templates it can take quite some time. Since the instantiated functions are weak symbols, N - 1 out of N instantiations for given argument set that’s instantiated N times in your whole project should get removed by any decent linker. Congratulations, you have just spent 3 minutes doing nothing but template instantiations.The previous paragraph has one blatant lie in it. I wonder whether you’ve spotted it.
The cake…
Here’s the aforementioned lie. In some cases the compiler does not need to know the template definition in order to use it. To be precise, the instantiation step can be skipped for N - 1 out of N instantiations for given template argument set. Let’s look at how the “vanilla” (non-template) functions are used (usually):
- There is a function declaration in header file.
//header.h file int foo(int bar); - The function definition resides in implementation file.
//impl.cpp file #include "header.h" int foo(int bar){ return bar; } - A translation unit that wants to call the
foo(int)function includes a header file with it`s declaration.// other.cpp file #include "header.h" int baz(){ return foo(5); // Neither the definition nor address of foo is known at this point. // Hence, the call is saved for resolution at link-time. } - The call is resolved at link-time - the address of
foo(int)is placed at “call” site.
On the other side of the spectrum, a “call” to function that’s a product of implicit template instantiation goes as follows:
- There is a template definition in header file.
//header_with_template.h template<typename T> T identity(T val) { return val; } - There is a translation unit that wants to use the template.
// implementation.cpp #include "header_with_template.h" int baz() { return identity(5); // identity template is implicitly instantiated // at this point for int argument. }Definition of
identity<int>is present in this translation unit and any other translation unit that wants to useidentity. - There is nothing to resolve at link time - moreover, since the definition is available at call site it can be inlined by compiler.
The problem lies within redundant instantiations. To deal with that, let’s prevent the compiler from performing it. It cannot instantiate a template if it does not know it’s full definition. Going back to the last example..
- There is a function template declaration in header file.
// mytemplate.h template<typename T> T identity(T val); - There is a function template definition in implementation file along with explicit instantiations.
// mytemplate.cpp #include "mytemplate.h" template<typename T> T identity(T val) { return val; } template // explicit template instantiation. int identity<int>(int val); - Finally, an end user uses only .h file - it cannot instantiate the function template, so no work is performed. The symbol is left for linker resolution.
// mytemplateuser.cpp #include "mytemplate.h" int baz() { return identity(5); }
Hey.. Doesn’t that remind you of an “ordinary function” approach?
… is a lie.
There are few drawbacks associated with this approach though..
- The call to instantiated function is no longer a candidate for inlining, since the function body is not known in given translation unit.
- Explicit instantiation is performed beforehand - types of arguments have to be known…
- And if you try to fight it by instantiating all known usages of given template in one translation unit, the same TU can quickly become bloated by dependencies that it does not really need (except for explicit template instantiation.. hopefully your headers are fine-grained!).
Last point is very important - I would advise against compensating for minor losses in multiple translation units by paying a potentially huge cost in one TU. I have once tried to disable implicit instantiations for some single-argument template which has been instantiated with 10 different argument types across whole project. It quickly turned out to not be worth it.
I must mention though that the first of the listed drawbacks can be remedied by LTCG. I hope you recall that LTCG can help immensely with inlining cross-TU function calls.
Template definition erasure is not very helpful for library authors though - in case function template is exposed as a part of library interface, there is no possibility of “hiding” the template implementation and improving the build time, because then the library user won’t be able to instantiate the template with their own list of arguments.
Extern templates to the rescue
C++11 introduced a very helpful tool - extern templates. It allows us to skip any implicit instantiation of a template with specific argument set. Compiler can then assume that the instantiated function is available in other translation unit and leave the symbol for link-time resolution. Consider our favorite (yet sub-optimal) template:
// header.h template<typename T> T identity(T value) { return value; }Declaring an explicit template instantiation can be achieved by specifying template name and argument set before it’s usage with a keyword (you’ve guessed correctly)
externin front. Hence, to prevent instantiation in some translation unit (and leave it up for linker to provide the function definition), the following construct should be used:extern template int identity(int); // Skip any instantiations of this template. bool biz(){ return identity(33) == 33; // The implicit instantiation won't take place. }What would be the use scenario for such a construct? Let’s say that
identityis used in two translation units..// first_user.cpp #include "header.h" int bar() { return identity(42); }// second_user.cpp #include "header.h" int baz(int val) { return identity(val); }The function template is instantiated implicitly in both cases for
int. However, the instantiation could be skipped in one of those (let’s picksecond_user.cpp). Thus,second_user.cppcontents should be changed in following fashion in order to make use of extern templates.// second_user.cpp #include "header.h" extern template int identity(int); int baz(int val) { return identity(val); }Now the call in
second_user.cppshall be resolved at link-time - and it shall use the symbol available infirst_user.cpp. Keep in mind that there must be at least one instantiation in whole project.Remember my rant about library authors in previous paragraph? Well,
extern templatecan be used in code that’s not really yours. It`s advantage over removing template definition from header in that the caller is responsible for managing the symbol (it will be left for linker resolution) and not the callee (who has to make the symbol inaccessible and force linker resolution in case of template definition erasure). Hence if you notice that this super-cool-yet-super-slow-to-instantiate-template-from-library is slowing down your build and the instantiations are repetitive across multiple translation units,extern templatemight be a good answer.That’s not a silver bullet!
There’s an issue though - which translation unit will be responsible for instantiating the template? There has to be one. I haven’t really found the answer to that question just yet, but the problem of instantiation responsibility is persistent across both definition erasure method and
extern template. Moreover, what if the template is instantiated in header file that you happen to pull in? Yep, the code can get pretty ugly. But if that’s the price to pay.. Personally I would be fine with that. Also, keep in mind that ability to inline the instantiated function template is lost once again - only for the mighty and glorious LTCG to reclaim it again.Summary
To recap, today we went through template instantiation methods and the ways to avoid doing unnecesary work. Two of the presented methods can be used in different circumstances:
- Template definition erasure is useful when there are a lot of callers for the instantiated function template, yet the possible domain of instantiation arguments is known beforehand (preferably most of them should be built-in types).
extern templateallows us to specify per-TU intantiation options. It might result in more boilerplate.
While both of them have their pros and cons (and different use cases, which I’ve just stated) I would lean towards using
extern template.Definition erasure is a global technique which requires user attention in order to support new type. On the other side of the spectrum,
extern templateis local to the current TU - using it in one TU does not surpress implicit function template instantiation in other TUs, so if a colleague tries to instantiate your template in theirs TU with cool and fancy argument set, they can expect reduced build time performance and not linker resolution error.Stop - hammer time. If you are interested in more details, give the following materials a look:
- Andre Haupt`s blog post about extern templates.
- cppreference.com entry on class templates (with few words about extern templates).
That’s it for today folks. Have a nice weekend. ;)
-
-
Posted on
Reduction of C++ project build time - Introduction
Hiho! It’s high time to brush the dust off of this blog once again. This time I will ramble about C++ build times. Do not expect this series to be uber formal - it’s more of a “food for thought” kind of thing.
Why you might care
While we pay relatively little attention to how our work is turned into bits and bytes (usually it occurs only when compiler screams back at us), high-level overview of build process and proper maintenance of project structure`s hygiene can have positive impact on our day-to-day job experience:
- Code could become faster to build…
- … And (compared to carelessly maintained project) it`s build performance might not deteriate nearly as fast over time.
- As a result, the throughput of CI pipelines (that are hopefully in place in your project) increases.
- Faster builds might make testing bugfixes under the debugger easier due to shortening time needed to perform one iteration of compiler-programmer feedback loop - since the code`s compile time is reduced, the time needed for compiler to verify it`s correctness is reduced. As a result the changes are easier to verify.
Having said all of that I must mention that build time improvements are not a free lunch - as we will see in forthcoming articles they often require making tradeoffs between build-time and runtime performance (or other resources, such as code size). Some of the techniques that might be helpful in reducing the negative impact of presented changes will also be showcased. This post introduces terms and concepts required to understand the problems and optimizations applicable to build process.
Build process overview
Disclaimer: A phrase “C/C++” might be used over the course of the following section. For the sake of this discussion I view C as subset of C++, because all of the build-time reduction techniques applicable to C can be used in C++ - the opposite is sadly not true.
C/C++ build process has three stages - preprocessing, compilation and linkage. Before diving into them though, let`s start with the notion of “translation unit” - which is a term that will pop up in this series pretty frequently. Translation unit is an output of preprocessing stage for a given source file. Thus, it is the final input of a compiler.
From a high-level perspective three stages of build process can be described as:
- Preprocessing - an optional process that accepts a source file as it`s input and produces another source file (translation unit) as a result. C++ preprocessor is fully compatible with C one.
C preprocessor can:
- Replace tokens in the source file with a predefined set of values (macros) - this is achieved via #define directive.
- Conditionally remove parts of text file based on preprocessor state - also known as #ifdef, #indef directives.
- Embed other source files within the source file - or just #include directive.
- Compilation - translates each translation unit into object files. An object file contains machine instructions. Additionally a compiler might optimize output machine code. Note that the result file is not yet executable at this point - this is responsibility of a linker.
Compiler structure is generally divided into two parts - frontend and backend. The former is responsible for parsing the source file and translating parsed code into an intermediate form that’s understandable by backend. The latter takes foremenetioned intermediate form, (optionally) optimizes it for given platform and generates machine code. There could also be a middle end between the two forementioned parts - it can optimize code in platform-independent manner (for instance by folding constant literals - statements like
500 + 3can be resolved to503at compile time, thus eliding the computation at run time). - Linker - resolves dependencies between translation units that participate in a build process. An example of a dependency between two translation units would be the call to function defined in other .cpp file. Linker also produces the final output file. Linker`s input consists of all object files that were produced by the compiler in the preceding step.
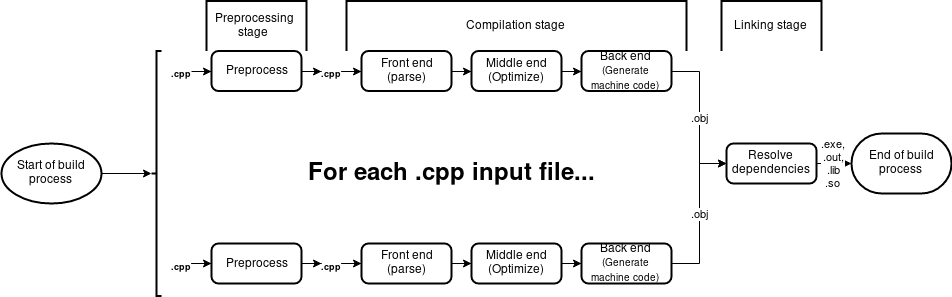
Classic C/C++ build process model. As we can see the path from .cpp to .obj can be parallelized (assuming no system-wide resources that are required by compiler). Soon we will see whether that can be exploited.. :)
Deceptive #include statement
The #include preprocessor directive includes source file (identified by it`s first and only argument) into the current source file at the line immediately after the directive (source: cppreference). It is pretty deceptive in a way, because what we see in the source is not what we get - a 5 line .cpp file can be expanded to thousands of lines of actual source code. The contents of included files are compiled like any other code. While it may seem obvious (it is #include after all, right?) I feel that it is easy to get wrong. Header files should be as tidy and fine-grained as possible.
What is inlining all about?
Inlining a function call means replacing the call instruction with actual contents of a function - thus improving program performance. Of course not every function call can be inlined - for starters current compilers use heuristics to determine whether the call should be inlined, because doing so introduces additional program size overhead. Additionally it is only possible to inline calls to functions whose definition is present in current translation unit. Hence any function call that has to be resolved by linker is impossible to inline (barring LTCG - we will get to that in a second).
#include was mentioned a few phrases prior to this one, because it (indirectly) allows to inline some of the function calls. For instance it is common practice to put function templates in header files. Since this template lands in the source of it`s dependents, the compiler can inline the call to the function.
Hello LTCG - link time code generation
Recall that in order to inline a function call compiler must have access to the function definition in given translation unit. Hence the function we want to be inlined has to be accessible in the translation unit. This can lead to bloat - if the same function is “costly” to compile (it`s compilation from front end through back end takes quite a lot of time), then each translation unit that depends on it has to pay the price of building said function. This is the opposite of reuse. However, apparently cookie can be had and eaten at the same time.
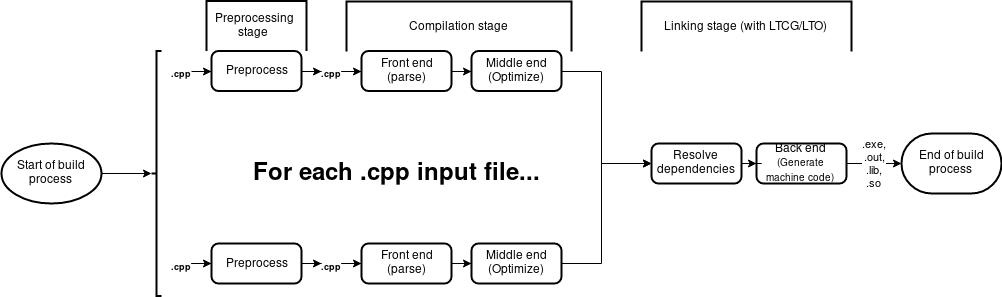
Classic C/C++ build process model. Link Time Code Generation is a technique which - as the name suggests - delays code generation part to the link time. Thus various optimizations (among which is inlining function calls) can be applied to whole codebase. Contrary to compiler, linker has access to whole codebase - hence it does not have to emit a function call when inlining it would be fine too.
Why would I bring that up though? One of the things that shall be addressed in future parts of this series is dealing with redundancy. Heads up - fighting it might have negative impact on program performance due to the reduced possibilities of inlining function calls… which is exactly what LTCG is good for. While LCTG should not improve build times substantially (I guess it might actually lead to slight decrease) it is worth employing to reap benefits of good performance at both runtime and build-time.
Takeaways
Today we addressed the build process (from a very high-level perspective). Hopefully it is a good foundation for future parts of this series. As with most things, reduction of build times is a game of tradeoffs. It is important to understand what these tradeoffs are and whether this mouse is worth chasing. In the next post I will address techniques useful in reducing the impact of templates on your codebase. Stay tuned!
- Code could become faster to build…
-
Posted on
Yet another turn
Do you remember Pychelor? Yes, I’m talking about this little project that never really took off. Guess what, it did not take off because I talked out of my ass. again.
Hopefully it will change. It’s time for bLog. That is binary logger. I hope to release PoC (which - frankly - I have ready) by the end of October. I already have plans for improvements, however - given that it’s the base of my bachelors - I needed the first version to be rather easily proven with mathematics.
What is bLog all about? It is a format for log storage. Data is stored in intermediate language, which is then interpreted to restore final file. It uses a dictionary to avoid storing long printf strings.
Hopefully this will work, Peter
-
Posted on
Language barriers
Straight to the point - due to my neglectance I have fucked over two of my personal projects at the same time. Namely, back in 2017 I have set up some ,,issues’’ for Hacktoberfest contributors. Vast majority of contributions was related to translating strings into different languages.
Guess what, TicTacToe-C has received only these kinds of PRs. Statula was a bit better, but a year ago I was less competent than I am now (that is not to say that I’m by any means capable of maintaing OS project, don’t get me wrong).
Surprise, surprise - I have already received six pull requests with translations. It is shitty situation, because:
- I cannot validate these PRs due to obvious language barriers.
- These kinds of tasks seem to have low engagement point - nowadays I feel like “newbie-friendly” task should still require her/him to sweat a bit. Even if he/she is not capable, it’s fine - we should be able to guide him/her through. Translating ten strings is relatively straight-forward and brings little to the table.
-
Those who actually spent some of their precious time will feel rejected. And it’s really shitty.
I have nothing to say but “sorry”. Overall, all translations will be rejected. Better yet, I will need to think about some kind of resource system to maintain this type of content in my projects. It is also redundant to try to gather OS community around your projects without giving them engaging tasks and actually caring for the project. If I don’t visit my github nowadays, no one else will.
I’m sorry.
Best regards, Peter
-
Posted on
Pychelor - the ,,Why''
After some exposure to distributed systems, I have found a perfect subject for my bachelors that involves one of my favourite subjects, statistics. This is Pychelor in a nutshell - data analysis and distributed systems (yes, data analysis is not equal to statistics).
Pychelor’s sole purpose is to make tracing events in distributed applications easier, even in dire times of unmet deadlines and ringing phones. It shall allow developers to trace the performance of their code in context thanks to system load tracking.
Let’s use a simple distributed system (in a supervisor-worker relation), where each participant of such system might have it’s own log, either condensed into one file (which I would call event log - even though it fits the following usage just as well) or split into multiple logs per functionality. Each worker is connected to one and only one supervisor, however one supervisor can be connected to many workers. Let us assume that should the communication between separate working units be required, it will be handled by supervisor - a proxy. Debugging such architecture is tricky for a variety of reasons:
-
Ease of using logs for debugging purposes (when looking at one worker and one supervisor) is strictly dependent upon the implementation of supervisor’s logger - should it condense multiple “event streams” (that is - multiple sources of events) into one file, searching through (quite often) few gigabytes of data (most of which is of no use, because it is not related to this particular worker) might be quite hard.
-
On the other hand, splitting the data into multiple files yields no context on the events - it is possible to deduce simple bugs that are directly connected with previous events in the log, however if the state of whole system comes into play, we are left empty-handed (unless you are willing to dig through five other files - but then.. are you lazy enough to call yourself a programmer?).
-
Raw size of data (regardless of used logging model) and the method of adding new information to log file (which is - most of the time - simply appending the information to the end of file) makes old data easier to access than new data. Make no mistake - this is related to the first point, however - while both of these are concerned with the size of a log - the previous argument was closely connected with information noise.
-
Logging directly from the process being observed means that - in case of failure - the log might get corrupted or lost altogether. Sharing single logger between multiple units (at whichever level of granularity) adds insult to injury in form of locking, which means that the event might not even be noticed. Surely, making robust software is hard.. The best we can do is try.
-
Reading through logs can be just as cumbersome - sometimes it’s hard to find relevant information in the noise of thread IDs, timestamps and all this good stuff. Hey, I’m not saying these are bad. That’s part of logging! However, they are (in my opnion) programmer’s best friend when enabled at just right moment - which is after locating the source of the trouble.
Surprise, surprise - I cannot deal with any of these. Would you expect that?
However, as I have said previously, the best I can do is try. Which is why I am gonna work on Pychelor. What I believe is key to solving aforementioned issues is to create a tool & bindings that would be:
-
Distributed, but with rich context - logs should be bound at lowest level of granulation, thus making assembling relevant logs a breeze.
-
Easy to mold - output logs should be prone to mutation at user’s request.
-
Robust - let’s avoid system failure, shall we?
-
Considerate of it’s words - the last thing I’d like to see tommorow in my job is that logs took up half a terabyte, most of which is probably noise.. =)
-
Lightweight - if possible, the impact of logging on the observed program itself should be negligible.
Someone has (probably) already came up with a better idea than mine, but hey. They got it all wrong..

As always, there is relevant xkcdSome of these things probably cancel out, but hey - I’m young, stupid and eager to experiment! Let the rockoff begin!
-
-
Posted on
Why, hello there Pychelor!
Yup. It’s happening.

It’s time to finally commit to one idea for my bachelors - which I have to hand in one year from now. I’m not forced to start now and I’m quite sure I won’t begin - just yet.
Pychelor is a new shiny thing of mine. Remember this dropbox connector? Scrap it. Who cares. This is Python. This is MACHINE LEARNING. This is new.
This project is all about doing things right the first time or not doing them at all - so I’m trying to do stuff that’s borderline impossible! =) Okay, enough chit-chat. Pychelors will be a daemon for *nix environment (hey, Windows support is right around the corner!) that will analyse the performance of arbitrarily chosen pipeline, pointing out potential bottlenecks and allowing the user to make adjustments as they see fit. As always, performance counts. =) I will cover this project’s design in the series of blog posts, which I’ll then turn into my bachelors. Yes folks, that’s what’s in the name!
See you around, Peter
-
Posted on
Bye bye GetOpt
Hi,
First and foremost, this is not an April Fool’s day post. For the time being I have no plans to maintain GetOpt++. Its officially an unwanted child of mine. I have new shiny things to take care of. I am looking into creating a Dropbox connector for C++. Not that I use their service, but hey. It will be fun. I hope. GetOpt was supposed to be fun, too.
Cheers Peter
-
Posted on
The sound of silence
Hey, Yes - I did pull out of this embedded project that I mentioned last time. To be quite frank, my life went south overall - I am no longer actively maintaining my projects (even though I did not admit it yet) which is a shame. I need to do that more. Maybe it is due to rather high workload - university is a pain in the ass. Well, just the mandatory part of it. I have met a few great people whom I owe a lot. But hey, at some point I have just lost the flame. All I need now is a bit of ember to rekindle my passion. :> I hope I’ll be a tad bit more active around here.
See you around, Peter
-
Posted on
How time flies - looking back
Hey, Long time no see. Few things have changed since my last post. First and foremost: I’m soon-to-be Junior Software Engineer. :] I’m gonna stay vague on that for now, but for all I know I am really proud of this accomplishment. I’m now in my sophomore year. Things are looking up. Other than that, recently I got pulled into Embedded project.. although I’m not sure if that’s my cup of tea. Additionally I’ve started using LaTeX - pretty cool, eh?
That’s it for now. I guess. See you around. :)
Peter
-
Posted on
Summer: Wrap up
Hey,
It’s the end of August. I guess I should briefly go over what I’ve done during my summer break (even though it will last for one more month).
First and foremost, I’ve finished 2 books during this 2-month span: “Design Patterns” by Gang of Four and “C.O.D.E” by Charles Petzold.
First one was kinda meh IMO. Not overall - I’ve progressed thanks to this book and it added few tools to my kit. I just can’t say that I had ‘a blast’ reading it. That’s to be expected out of reference tho. So no bad words for that, really.
“C.O.D.E” on the other hand.. It was great. Sure, it’s laid back, but it really helped me get a grasp of how computers work - even though I suck at physics and so I didn’t benefit from it as much as I could. It was definitely a good read though.
Currently I’m going over CLRS - RB trees are weird. That’s it.
When it comes to my projects - it turns out that I’ve introduced bigass bug in v0.1.9 of Statula. It seems to be fixed now, thankfully. TicTacToe has come a long way too. I still have something in store for you guys (hi mom), but I can’t really get a grasp of how it should be incorporated into my project. Small hint: Dynamic programming is what I’m looking at. :)
There is also GetOpt++. That’s my first C++ project and it’s relatively small. I will see what I can do with it in the future.Saying that I worked my ass off throughout the holidays would be an overstatement. I pretended to do so.
I’m kind of confident going into my first ever round of interviews, though. Let’s hope for the best!See ya,
Peter -
Posted on
Holidays
Hey,
So I am officially a grown-up adult - I have turned 20 years old yesterday. It’s funny how fast time flies by.
Perhaps I should not worry - there is still some time. Or atleast that is what I am being told all the time.I have recently started practicing for upcoming Google STEP interviews with people from TwitchLearnsProgramming(They rock btw!) and I am really enjoying it.
Really, I do - I mean, it was kind of stressful at first, but with every interview I am getting ever more confident in my skills.Back to the original point - I am going into my second year at uni. And so, I’ve been told a few times that “there is still time” for me to learn. Take it easy cowboy, eh?
I mean, I see where all of this comes from - it’s not like majority of programmers start as early (or late - whichever way you chose to put it) as in their freshman year.
Still, I am a special flower nope, just kidding . I can’t really sit around and do nothing (well, I can and I do it to a great success nowadays, but that is not what I mean).
Our time is limited and so are the opportunities. Perhaps I will look back at this post one day and mumble “Oh gosh, was I a goof..”. I am fine with that.When it comes to slightly more relevant things: today I have refactored a good chunk of code in TicTacToe. It’s available on GitHub - take a peek!
It was painful to go through, but that is what this project was for - making mistakes and first steps. It is still pretty easy to mantain, and that’s what I value the most.So yep, reading books, trying to improve my CV and praccing for interviews. That’s what I do nowadays.
Fun? What’s that? Haven’t heard of that since few years. :P
And how do you spend your holidays? Tweet me!Signing off,
Peter -
Posted on
At the crossroads - approaching Statula 0.2.0
Hey, A small update - we are quickly approaching v0.2.0. I plan to roll out few minor updates (v0.1.9 will include few additional starting parameters).
What is here to come in 0.2.0? io.c will definitely change - I plan to make read_data more abstract in order to support different notations.
Let’s take a look at a simple dataset:2 2 4 2 2 2 5 4
What if we could represent it as:
5x2 2x4 5
The benefits are not apparent at the first glance, but that is one of many possibilites. I will also refactor some of the functions and their names - I would like them to be as descriptive as possible (and “strings” does not really speak for itself).
v0.2.0 will also bring some incompabilities - amongst which is forementioned abstracted read_data function. Additionally, one of the added command-line functions will bind statula.c/io.c and the rest together. I would like to avoid that, but it seems inevitable. I could either stay true to my intentions for the project (that is - portable library for statistics).
It is apparent that this will hold the project back in the long run. Some incompabilities were already introduced back when dataset structure was added. From v0.2.0 onwards we steer towards command-line tool.
Till the next post boys and girls. :)
-
Posted on
Rant on humbleness
Hey,
It’s time for some incoherent rambling. What is progress and how can we measure it as beginners? Should we acknowledge our lack of experience? I think answering those questions is kind of tricky. Progress is (amongst other definitions) becoming more proficient at something, be it singing or programming. Every beginner struggles with quantifying their experience - it is really hard!
Fear not newbies. If you’ve ever felt like a dumbass while using scanf (fuck that shit by the way) then you have probably progressed at the same time - questions such as “What do I need ampersand for?” have probably went through your mind. Those who took time to google it instead of accepting this as a fact have stumbled upon pointers. Good for them. Don’t get me wrong, I’m beginner myself (and I will be for the rest of my life) but I believe that such encouragement might keep someone going. It’s really easy to just abandon something altogether due to the lack of visible progress.
Trust me, you must keep going. Looking back, I’ve felt dumb for the vast majority of my journey with programming. And I’ve felt bad about feeling dumb - wouldn’t call that a pleasant experience. ;) Just embrace it because your adventure is made of every little step that you take. Surely, we remember only the big moments. However, those little steps, improvements, tweaks should not be frowned upon.
How many Google CEO’s would we have if only everyone was perfect? Well, a few. But that’s not to say that not being at this prestigious position means being somehow worse. Just embrace the fact that you are still learning. Feeling dumb is integral part of the process.
To answer the initial question - in my opinion progress is not clearly measurable because we evolve constantly.
I’ll finish this post of with some food for thought. If you were to ask children at kindergarten “Are you a genius?” then you could expect vast majority of the responses to be affirmative. The same question in primary school could yield around 50/50 results. Secondary school? Don’t bother, noone will raise a hand. And that’s sad. We kill our ability to dream.
Don’t belittle yourself. :) -
Posted on
Why, hello there!
Hey,
So I thought that it might be a good idea to finally start blogging. I guess that I will keep the atmosphere rather loose in here, however I might shoot a serious post up from time to time.
Right now I am working on Statula and TTT. It is pretty funny when you go back in time and see yourself starting such a toy project - I’ve never really considered TicTacToe as something that might be used by someone else.
I guess it’s just programming for the sake of programming right now. Don’t get me wrong, I’m not set on this project being a failure or anything along those lines - I actually consider it a success due to the amount of knowledge I’ve got thanks to it. If you look at it from proper perspective, even such a simple concept as TicTacToe can be quite challenging if you have the will to see those challenges - at the very start creation of AI seemed nigh on impossible. Take a glance at it today - not only is it working, it’s also unbeatable (and that’s a success since non-minmax implementation was wanky to say the least).
Also, there is no such a thing as a failure in programming. There is only a lesson.
Now, another milestone would be either creating a server for it or an user interface. Both options seem rather overwhelming at first, however I already have some concrete basis for server - that is, I thought out whole structure of networking. When I finally sit down to sockets in C, I will probably get it going.
UI is a bit tricky for me. I’ve successfully recreated kilo (check the tutorial out, it’s really good) so I have that going for me. I will probably use ncurses though - it just seems way more convenient.
I’m not the user interface guy. I’m definitely not. And that’s why my second project, Statula, doesn’t feature one - and never will. It’s not that I run away from problems. I have one thing in mind with this program - performance. I couldn’t care less for UI in a program that has one job, and it’s supposed to do it well.
I guess that’s it. My first blog post. Boy, was that quick. Maybe I will type something up in a day or two.
Have a nice day boys and girls!
subscribe via RSS